新闻动态
News


前言
在人工智能的浪潮中,技术创新持续推动智能应用的疆界拓展,涵盖自动驾驶汽车在错综复杂环境中的决策优化,以及医疗健康领域内对疾病的早期精准诊断。在这一快速发展领域,训练与推理的高效整合成为AI应用成功的关键因素。传统上,这两项流程的分离执行限制了资源效率,导致资源利用不充分和迭代周期冗长,严重制约了AI技术的快速迭代与应用落地。然而,容天推出的Omnisky ML BOX训推一体解决方案,融合NVIDIA NIM,旨在打破这一界限,实现训推一体的无缝衔接。
Omnisky ML BOX结合NVIDIA NIM,提供高密度算力和开箱即用的训推一体服务。NVIDIA NIM优化 AI 推理,支持多模式生成式AI,确保全球可用性和性能。为追求高效率的团队提供强大支持。Omnisky ML BOX训推一体解决方案的开箱即用特性和NVIDIA NIM的推理加速服务,共同提升了行业应用的效率和性能,推动多模态大模型产业落地,释放极致算力。
关于训推生产力
训练与推理的定义
训练:训练指的是在大语言模型的学习过程中添加数据集,不断进行优化,调整权重参数以具备适应各种任务的学习能力。这个过程需要大量算力资源,时间和能源。训练的步骤一般来说可以分为以下几个部分:
数据预处理
模型定义
模型训练
模型验证
推理:推理在训练之后。是在训练好的模型基础上,对新的、未知的数据进行预测的过程。这个过程不需要额外的数据,只需要输入待预测的数据即可。推理的步骤一般来说可以分为以下几个部分:
模型加载
数据输入
模型预测
结果后处理
训推一体机的意义和优势
大模型训推一体机一般指集成了大模型训练和推理功能的“全栈式”人工智能设备,通常包含中央处理器(CPU)、图形处理器(GPU)、存储器、操作系统、深度学习模型等软硬组件,能通过大规模数据训练掌握数据处理和预测等能力。
与通过应用程序编程接口使用大模型功能相比,企业利用训推一体机实现大模型部署具有多方面优势。首先,训推一体机可以针对企业的特定业务需求提供“开箱即用”的定制化大模型解决方案,并通过软硬件协同优化提高性能,降低大模型部署、业务方案建设和调适的门槛。例如,北京容天汇海科技有限公司基于NVIDIA硬件算力基座,NIM推理微服务和TensorRT等推出了“容天医疗大模型训推一体机”,可面向智能门诊、辅助诊断、医院管理建设等智慧医疗重点建设领域,提供智能化、高效实时的解决方案和决策支持。
其次,由于训推一体机将所有计算资源集中到一台设备上,在大规模数据训练中可大幅减少数据传输时间,提高计算速度和模型训练效率,使企业能够更快捷地使用和管理资源。
此外,本地化部署的训推一体机能最大程度保障数据隐私和模型安全可控,满足企业对数据安全监管的需求。英国《金融时报》日前报道说,在企业内部署的大模型训推一体机产品正在对一些大型科技企业提供的基于公共云的人工智能服务形成冲击。
该报道说,近期曝出的人工智能企业安全漏洞加剧了用户对数据安全的担忧。例如,ChatGPT将用户的搜索历史分享给他人,以及韩国三星的员工在使用ChatGPT处理工作时无意间泄露了公司的商业机密等。报道援引中国科大讯飞董事长刘庆峰的话说,机构需要能够保护他们的数据,而建立私有云是防止有价值数据泄露的方法。
NVIDIA NIM——推理服务革命
什么是 NVIDIA NIM
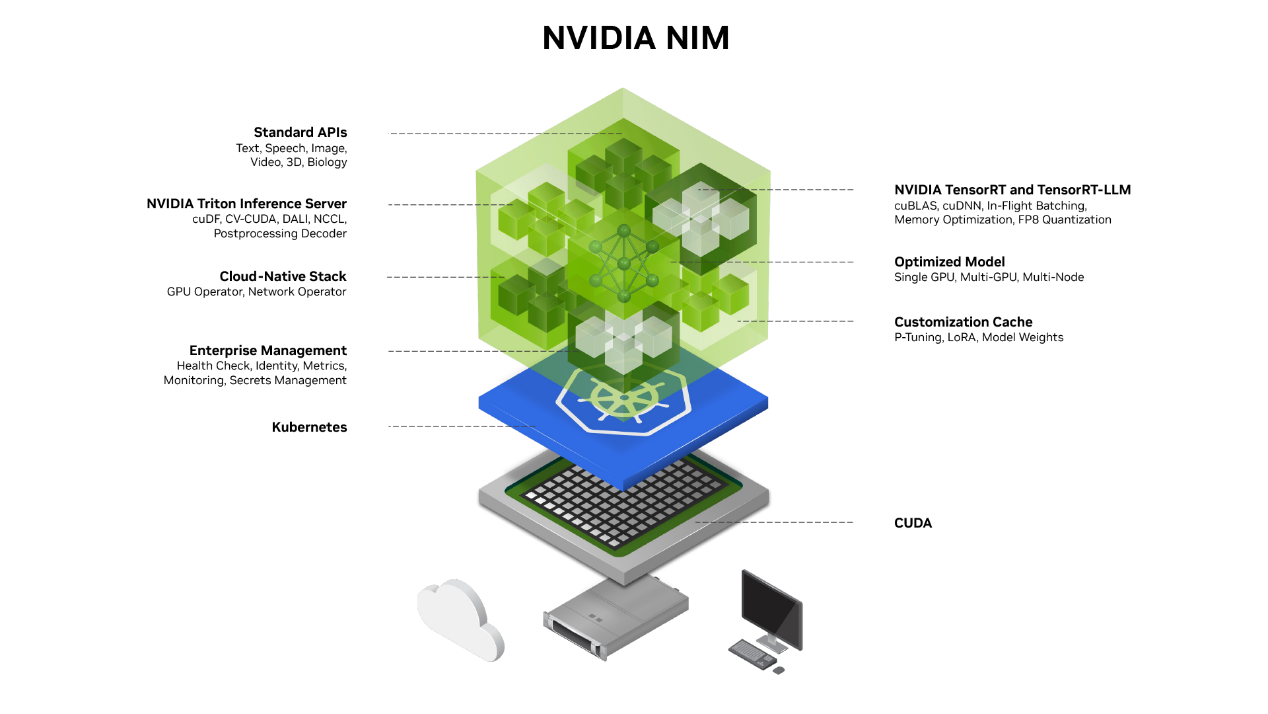
NVIDIA NIM (NVIDIA Inference Microservices)是 NVIDIA AI Enterprise 的一部分,是一套易于使用的预构建容器工具,属于一种推理微服务,目的是帮助企业加速生成式 AI的部署。这些预构建的容器支持广泛的 AI 模型。NIM 微服务只需一个命令即可帮助企业客户部署AI模型,以便使用标准 API 和几行代码轻松集成到企业级 AI 应用程序中。
NIM 基于可靠的基础 (包括 Triton 推理服务器、TensorRT、TensorRT-LLM 和 PyTorch 等推理引擎) 构建,旨在促进企业客户根据其自身需求和选择大规模无缝 进行AI 推理,从而确保企业可以满怀信心地在任何地方部署 AI 应用程序。无论是在本地还是在云端,NIM 都能高效实现大规模加速生成式 AI 推理。
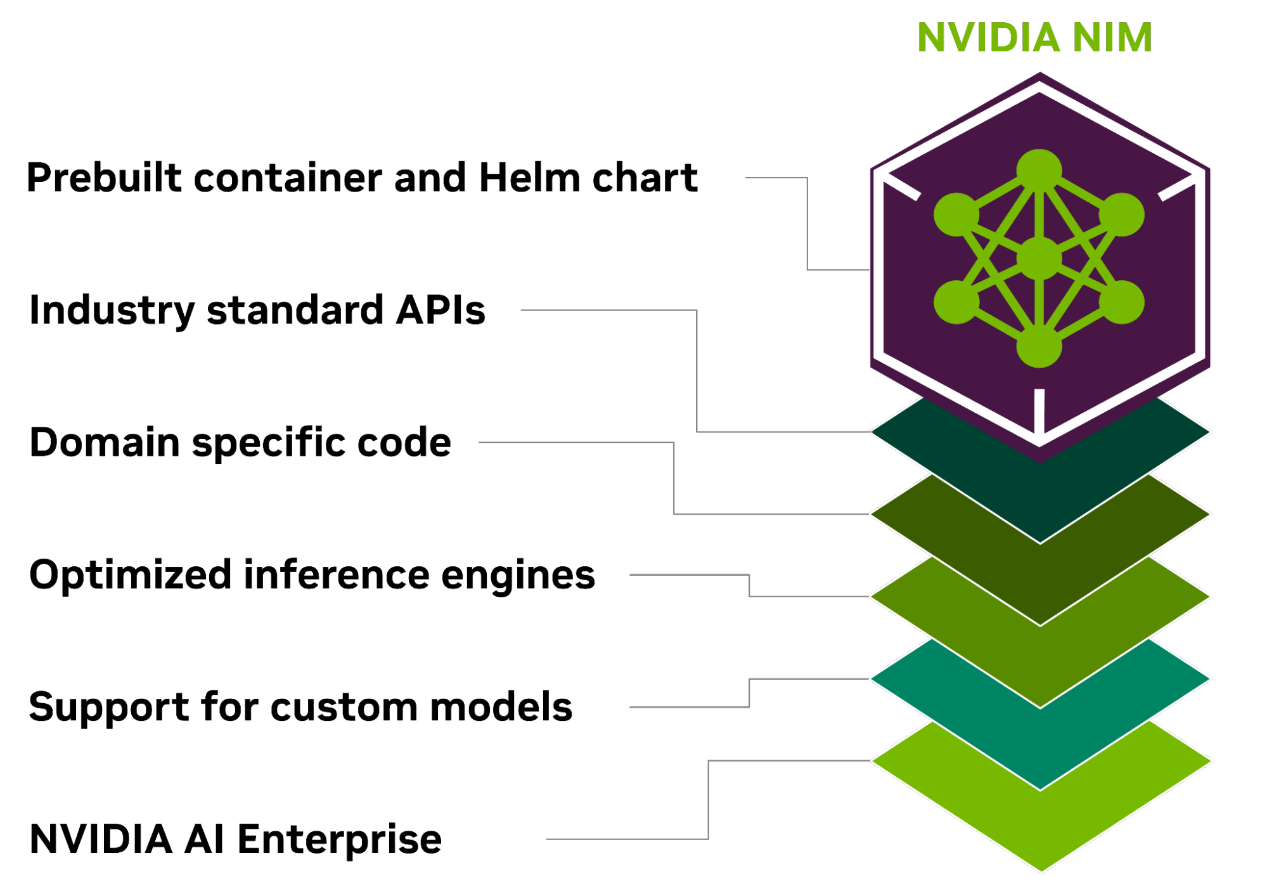
为什么使用NVIDIA NIM进行开发
优化的推理引擎
NIM 针对每个模型和硬件设置,基于经过优化的推理引擎,包括 TensorRT、TensorRT-LLM 和 Triton 推理服务器等,在加速基础设施上提供尽可能好的延迟和吞吐量。有效降低了在扩展推理工作负载时运行推理工作负载的成本,并改善了最终用户体验。除了支持优化的社区模型外,开发者还可以基于从未离开数据中心边界的专有数据源对模型进行对齐和微调,从而实现更高的准确性和性能。
简化开发流程
通过使用NVIDIA NIM,开发者可以大幅度简化开发流程。NIM提供了热门大型语言模型 (LLM) 开发框架中的行业标准API和库,使开发者能够轻松将AI应用集成到应用中。此外,开发过程对于门槛要求低,即使是入门者也可以随心所欲构建自己的应用。
可随时随地部署
NIM 专为可移植性和可控性而构建,支持跨各种基础设施 (从本地工作站到云再到本地数据中心) 进行模型部署。其中包括 NVIDIA DGX、 NVIDIA DGX 云、 NVIDIA 认证系统、 NVIDIA RTX 工作站和 PC。
预构建的容器和 Helm Chart 打包了优化模型,并在不同的 NVIDIA 硬件平台、云服务提供商和 Kubernetes 发行版中进行了严格验证和基准测试。这支持所有 NVIDIA 驱动的环境,并确保组织可以在任何地方部署其生成式 AI 应用,同时保持对其应用及其处理的数据的全面控制,维护生成式 AI 应用程序和数据的安全性和控制权。
基于行业标准 API 进行开发
开发者可以通过符合每个领域行业标准的 API 访问 AI 模型,从而简化AI 应用的开发。这些 API 与生态系统中的标准部署流程兼容,使开发者能够快速更新其 AI 应用 (通常只需 3 行代码)。这种无缝集成和易用性有助于在企业环境中快速部署和扩展 AI 解决方案。
模型可针对特定行业领域
NIM 通过几个关键功能满足了对特定领域解决方案和优化性能的需求。它包含特定于领域的NVIDIA CUDA 库,以及为语言、语音、视频处理、医疗健康等各个领域量身定制的专用代码。这种方法可确保应用程序准确无误并与其特定用例相关。
支持企业生产环境 AI
作为 NVIDIA AI Enterprise 的一部分,NIM 采用企业级基础容器构建,通过功能分支、严格的验证、通过服务级别协议提供的企业级支持以及针对 CVE 的定期安全更新,为企业 AI 软件提供坚实的基础。全面的支持结构和优化功能突出了 NIM 作为在生产环境中部署高效、可扩展和定制的 AI 应用的关键工具的作用。
Omnisky ML BOX训推一体算力基座解决方案
ML BOX训推一体解决方案介绍
Omnisky ML BOX 是北京容天汇海科技有限公司针对训练推理服务及高性能计算需求推出的高端人工智能训推一体算力基座,旨在提供开箱即用的训推一体化解决方案。ML BOX 搭载 NVIDIA 智算芯片,结合 NVIDIA 推理引擎和加速库,提供极致的算力体验。通过预集成多种开发模板和工具套件,ML BOX 降低了 AI 开发的门槛,使用户能够快速启动项目并高效推进。ML BOX 支持一站式 AI 开发,覆盖了从概念构思到产品实现的每一个阶段,基于用户友好的界面和精心构建的软件生态系统,为研究人员和开发者提供了无缝接入的平台,确保了研究人员与开发者能够即刻投身于创新前沿,极大地加速了 AI 项目的开发进程和创新的迭代周期。

NVIDIA NIM和Omnisky ML BOX训推一体解决方案联合优势
NVIDIA NIM与Omnisky ML BOX训推一体解决方案的结合共同构建了一个强大的开箱即用式训推一体算力平台,为推动人工智能训推生产力作出卓越贡献。Omnisky ML BOX训推一体解决方案的高密度智算芯片与NVIDIA NIM优化推理引擎相结合,可构建一套高吞吐,低延迟的训推生产力基座。NIM简化开发,可快速部署的特性与Omnisky ML BOX独立部署,开箱即用的能力结合,为用户提供一个易于开发部署,快速落地使用的解决方案。
NVIDIA NIM与Omnisky ML BOX训推一体解决方案的结合,为用户提供了一个开箱即用的高性能计算训推一体平台,推进训推生产力持续健康发展。
