新闻动态
News


一、什么是 MLOps?
MLOps 作为人工智能工程化重要内容,连续两年进入 Gartner 数据科学与机器学习技术成熟度曲线。国内外头部企业已纷纷推出 MLOps 平台或工具。那么 MLOps 到底是怎样?
在 AI 工程化实践中,一直以来面临的核心问题是如何将 AI 数据、算法、模型与实际场景相结合,构建更加复杂和完整的解决方案,为各行各业创造规模化的业务价值。而脱胎于 DevOps 的 MLOps 可以解决这类问题,使 AI 应用从小作坊的手工模式走向大工厂的流水线模式,促进 AI 规模化落地,是打通 AI 工程化最后一公里不可缺失的部分。
MLOps(Machine Learning Operations)——是面向机器学习的研发运营管理体系,目的是连接业务团队、AI 团队和运营团队,建立一套标准化的模型开发、部署与运营流程,以管理机器学习项目的全生命周期。
二、MLOps 的目标
1、加快从实验到产品的迭代速度
2、标准化机器学习的开发流程
3、提高模型的性能并确保其质量
4、促进研发/业务部门的协作
5、优化计算资源的使用
MLOps 作为机器学习时代的 DevOps,它的主要作用就是连接业务团队、模型团队和运维团队,建立起一个标准化的模型开发、部署与运维流程,使得企业组织能更好的利用机器学习的能力来促进业务增长。
简单举例,几年前我们对于机器学习的印象主要是拿到一堆 excel/csv 数据,通过 notebook 等尝试做一些模型实验,最终产出一个预测结果。但对于这个预测结果如何使用,对业务产生了什么影响,大家可能都不是很有概念。这就很容易导致机器学习项目一直停留在实验室阶段,一个接一个做 POC,但都没法成功“落地”。
近几年,大家对于 ML 项目落地愈发重视起来,对业务的理解,模型应用流程等都做的越来越好,也有越来越多的模型被部署到真实的业务场景中。但是当业务真实开始使用的时候,就会对模型有各种各样的需求反馈,算法工程师们就开始需要不断迭代开发,频繁部署上线。随着业务的发展,模型应用的场景也越来越多,管理和维护这么多模型系统就成了一个切实的挑战。
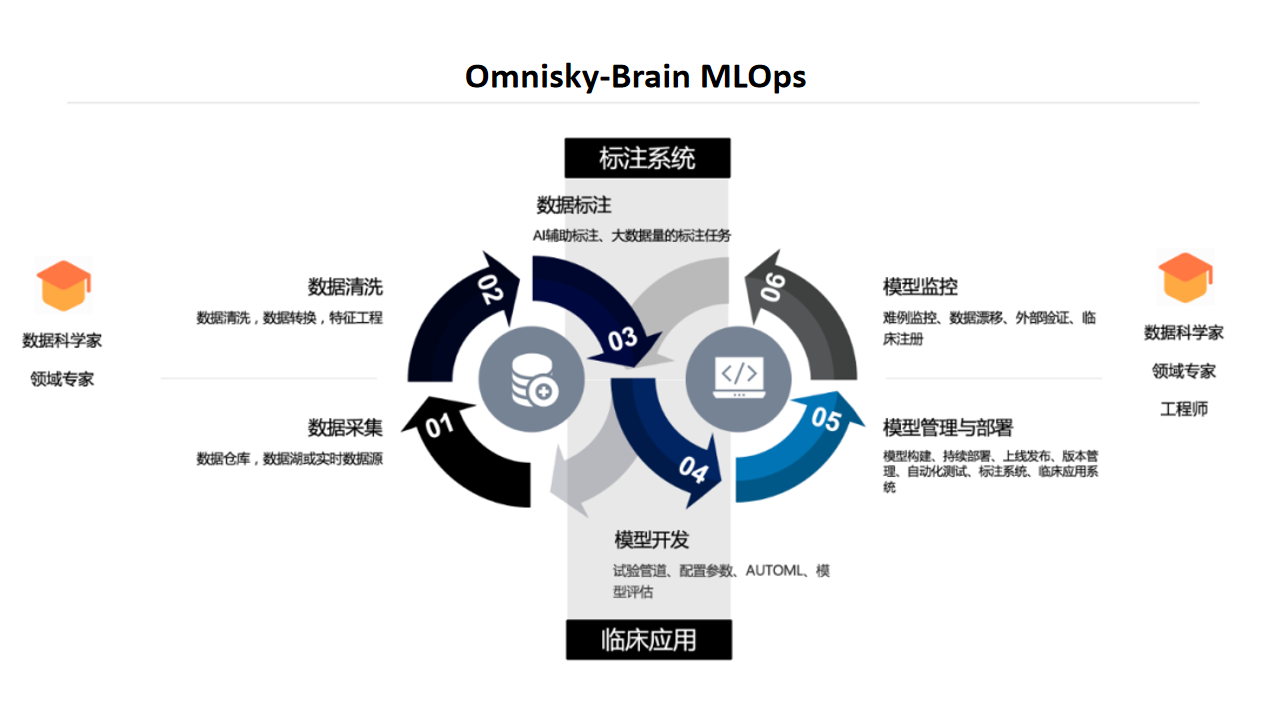
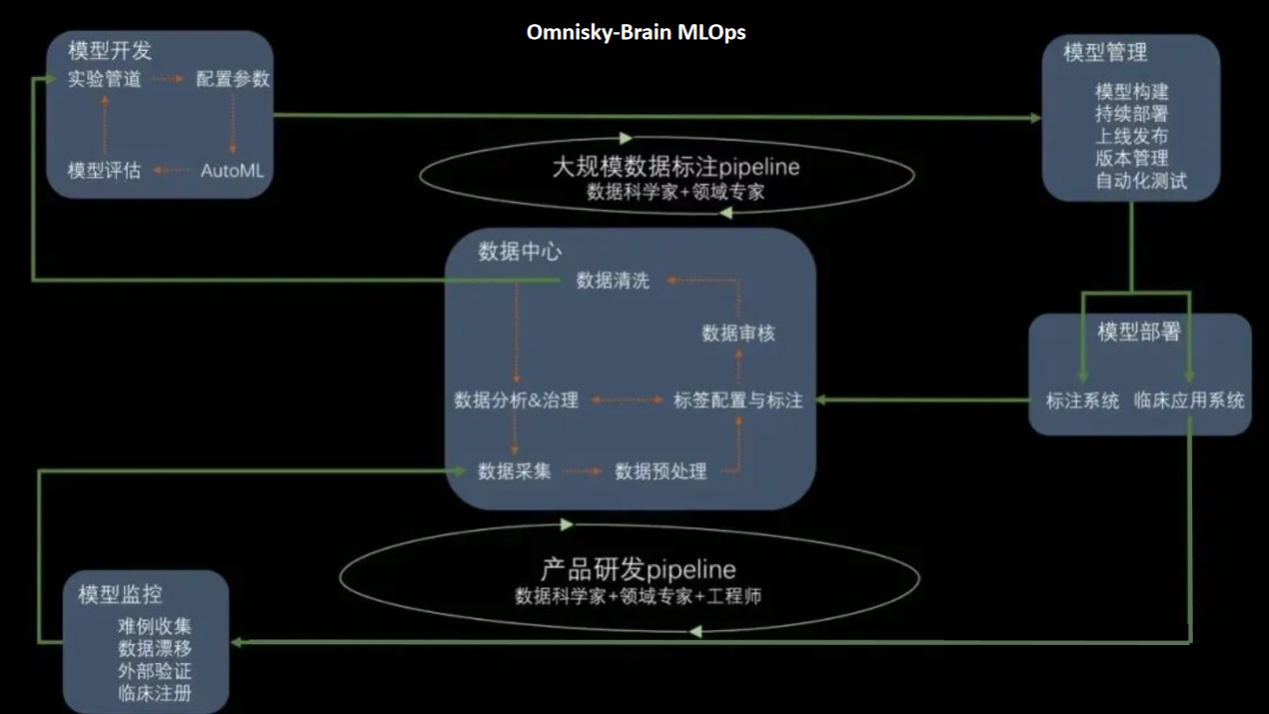
三、Omnisky-Brain MLOps
Omnisky-Brain MLOps 对企业有哪些价值?
1、通过各种工程上的最佳实践,提升了企业内部团队整体开发交付模型的效率。
2、由于项目运维成本的降低,大大提升机器学习类应用的 scale 能力,在企业内上线多个模型来为各方面的业务场景产出价值。
MLOps 的最佳实践 Omnisky-Brain
1、Omnisky-Brain 人工智能研发运营一体化平台基于 Kubeflow,搭建了一套低代码、无代码的数据科研平台,实现快速大规模数据标注,数据的管理和运营,项目和试验的搭建,模型的管理和发布。
2、基于 Omnisky-Brain MLOps,算法工程师一方面能更专注于擅长的模型构建过程,减少对模型部署运维等方面的“感知”,另一方面也让模型开发迭代的方向更加清晰明确,切实为业务产生价值。科研人员也无需关注软件环境、硬件配置和算法相关的代码工作,更专注于数据 insights 获取,让模型发布成为快速无感知的自动化流程。
四、Omnisky-Brain 能做什么?
Omnisky-Brain 集群管理模块
通过对集群资源的规划,作业调度,环境管理,性能监控等,提供一个可扩展、安全、高效、可靠的GPU集群服务,以满足各类机器学习工作负载的需求。
Omnisky-Brain 数据中心模块
数据接入:直接对接医院业务系统、数据仓库、数据湖等,实现业务数据和科研数据的无缝对接。并迁移到到平台后的数据存储,对科研机构、医疗机构、AI 企业的数据资产进行管理。
数据工程:包括数据清洗、数据转换、特征工程。根据业务形态的不同,这部分所占的比重可能会各不相同,但总体上来说这部分在整个模型开发过程中占的比重和遇到的挑战是比较大的。包括:
1、对于大量数据处理逻辑的管理,调度执行和运维处理。
2、对于数据版本的管理和使用。
3、对于数据复杂依赖关系的管理,例如数据血缘。
4、单病种数据库的建立。
数据标注:Omnisky-Brain 对大数据量的标注任务有很好的支持,依托强大的模型开发能力,内置多种 AI 辅助标注模型。以及在小范围样本标注基础上快速生成模型进行辅助标注,在逐渐提升模型准确性的基础上,不断提升辅助标注速度,满足大样本量的快速标注。
1、内置多种病种模型,快速建立大数据量标注任务。
2、基于小数据量标注,快速开发模型,不断迭代提升辅助标注准确性。
Omnisky-Brain TAO(Train,Adapt,andOptimize)AI 训练、适配、优化模块
模型构建方面提供 NVIDIA AI Enterprise 和成熟的机器学习框架来帮助用户训练模型,评估模型效果。包括:
1、模型开发过程中的结果评估与分析,包括指标误差分析,模型解释工具,可视化等。
2、模型本身的各类元数据管理,实验信息,结果记录(指标,详细数据,图表),文档(model card)等。
3、模型训练的版本化管理,包括各种依赖库,训练代码,数据,以及最终生成的模型等。
4、模型在线更新和离线再训练,增量训练的支持。
5、一些模型策略的集成,例如 embedding 的提取与保存,stratified/ensemble 模型支持,transfer learning 之类的增量训练支持等。
6、AutoML 类的自动模型搜索,模型选择的支持。

Omnisky-Brain Triton 推理服务模块
推理服务模块结合 NVIDIA Triton Management Server,通过弹性缩放、并发控制、流量管控等手段保证服务稳定性。利用模型管理、日志、监控、降级等机制构建健壮的推理系统,从而以高效、智能、可靠的方式为各类AI应用提供低延迟、高可用的推理服务。
