新闻动态
News


随着人工智能驱动的机器人和边缘设备的开发部署速度持续增长,下一代AI算法模型对于设备算力的要求也在逐步提升,从而应对实时并发运行的多模态AI应用场景。
例如在制造、零售、建筑、农业、物流等多种行业中,人机交互场景在不断增加,这些自主机器人必须同时执行3D感知、自然语言理解、路径规划、避障、姿势估计以及许多需要高计算性能和高准确度的AI算法模型。
NVIDIA为了应对这样的应用场景,给出一套优秀的解决方案——Jetson边缘计算模组。其中,Jetson Orin NX作为NVIDIA Jetson中具有超高性价比的系列,在提供卓越性能和一流能效的同时,可以全面运行的NVIDIA AI软件堆栈,为下一代要求严苛的边缘AI应用场景提供动力。
Jetson Orin NX超高性能
凭借高达100TOPS的性能,Jetson Orin NX模组可以在边缘运行服务器级的AI算法模型,并提供端到端的服务。与此前的Jetson Xavier NX相比,Jetson Orin NX为现代AI带来了更高的性能、能效和推理能力。
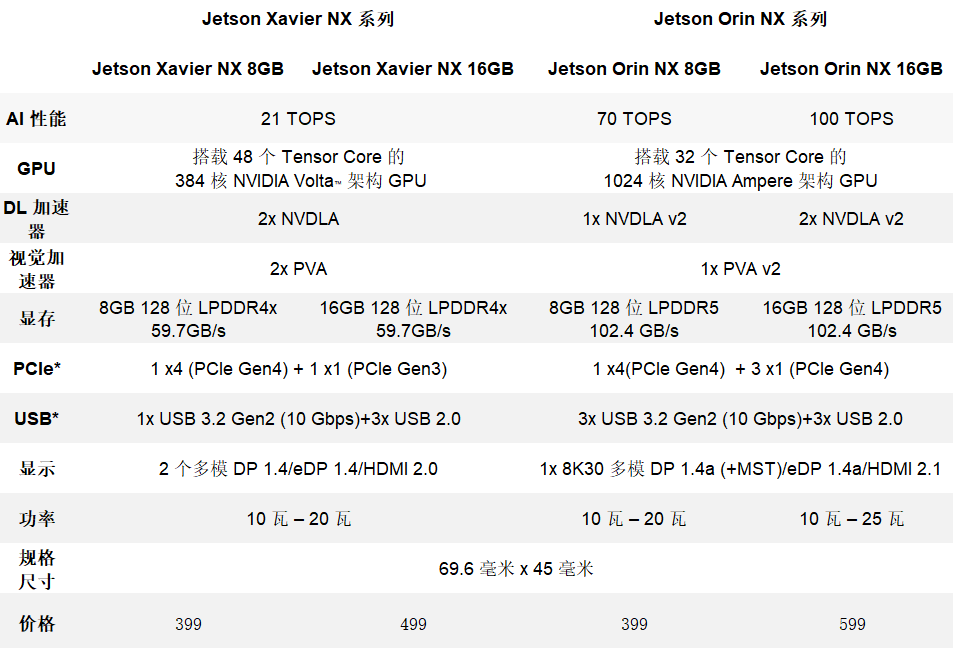
表1.Jetson Xavier与Jetson Orin能力和价格对比
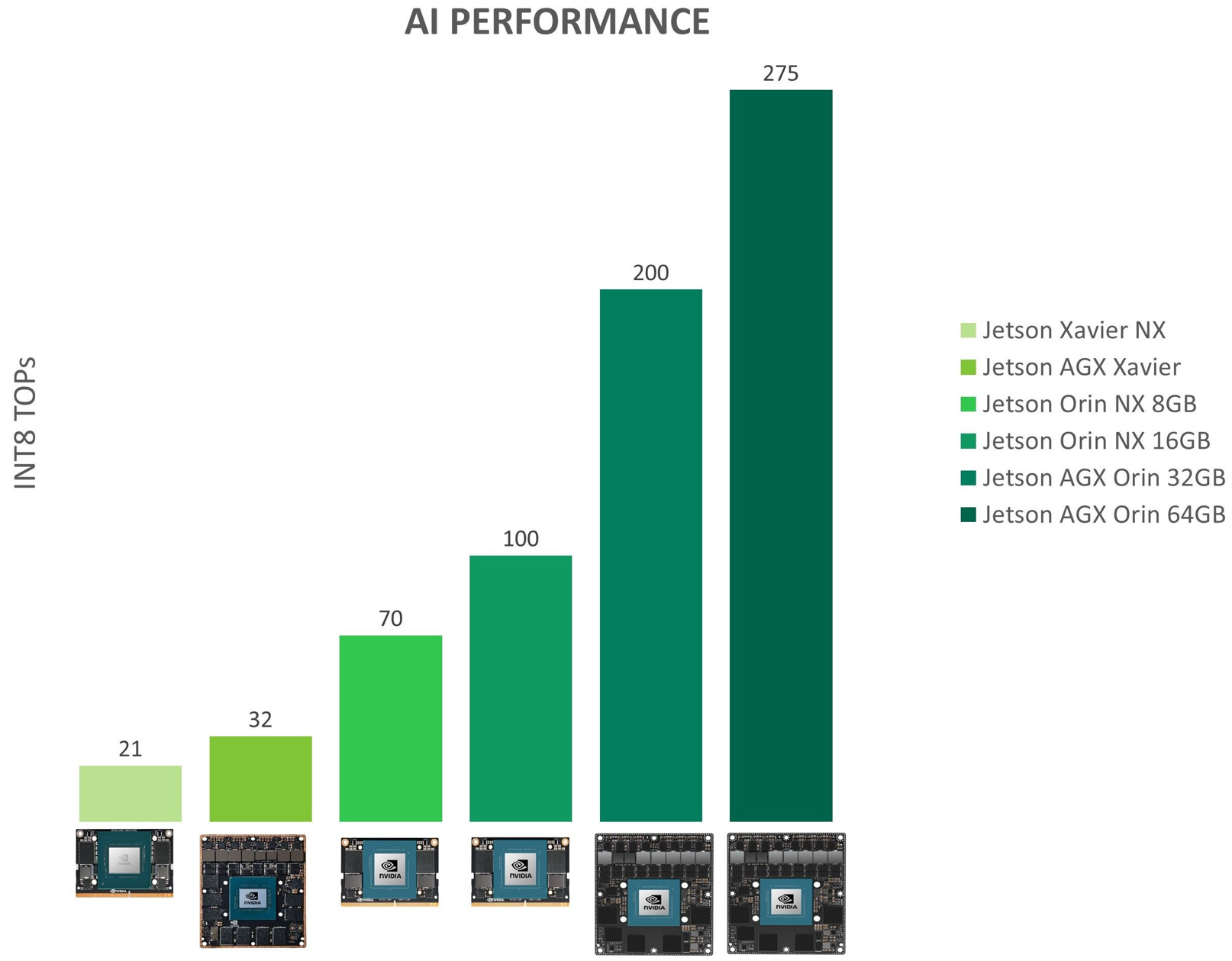
图2.Jetson Xavier和Jetson Orin模组AI TOPS性能比较
Jetson Orin NX以NVIDIA Jetson中最小的外形尺寸、可扩展的NVMe存储,相比Jetson Xavier NX提供5倍的性能升级(或以相同的价格提升高达3倍的性能),将更高级别的性能带入下一代边缘产品,如巡检机器人、无人机和手持设备等。

图3.Jetson Orin NX大小对比
Jetson Orin NX系列应用场景
Jetson Orin NX可以和NVIDIA强大的AI软件堆栈、SDK和软件平台相结合,作为高性能、小尺寸、低功耗以及有预算限制的嵌入式边缘计算设备,应用于制造、物流、零售、服务、农业、智慧城市、医疗保健、生命科学等领域的先进人工智能机器人、边缘检测设备和AI应用场景。
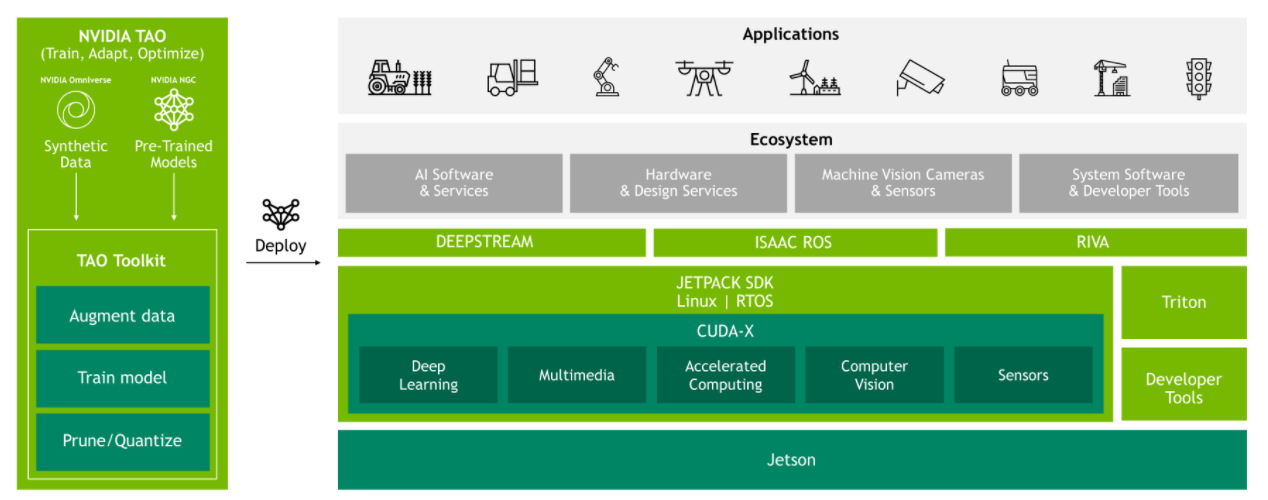
图4.Jetson软件概览
搭配NVIDIA JetPack 5.0,Jetson Orin NX与Jetson Xavier NX相比,性能同样也有极大的提升。NVIDIA JetPack是Jetson平台的基础SDK,为硬件加速的边缘AI开发提供了完整的开发环境,实现端到端加速:NVIDIA TensorRT和cuDNN用于加速AI推理、CUDA用于加速通用计算、VPI用于加速计算机视觉和图像处理、Jetson Linux Multimedia API用于加速多媒体......
JetPack中还包含NVIDIA-container-runtime,可在边缘端实现云原生技术和工作流,同时将AI算法模型容器化,使用云原生技术大规模管理这些模型,优化软件开发和部署流程。
为了在Jetson平台上快速开发完全加速的应用程序,NVIDIA还提供了适用于各种用例的应用程序框架:
1、DeepStream:快速开发和部署视觉AI应用程序和服务。DeepStream借助端到端的AI管道硬件加速插件,提供了超越硬件的推理加速功能。
2、Isaac:提供硬件加速的ROS软件包,使ROS开发人员能够更轻松地实现高性能机器人解决方案。
3、Omniverse:提供NVIDIA Isaac Sim,对物理环境进行高度的仿真还原、实现物理上精确的虚拟环境,以开发、测试和管理基于AI的机器人。
4、Riva:为自动语音识别(ASR)和文本转语音(TTS)提供最先进的预训练模型,这些模型可以轻松定制、快速开发GPU加速的对话式AI应用程序。
为了缩短可用于生产且高度准确的AI模型开发时间,NVIDIA提供一系列的工具来生成数据集、训练和优化模型,并快速创建可部署的AI模型。
用于生成合成数据的NVIDIA Omniverse Replicator,有助于创建大量多样化、高质量数据集以促进模型训练,在现实世界中这不仅很难,而且有时候是不可能创建的。使用合成数据和真实数据来训练模型,可以显著提高模型的准确性。NVIDIA NGC提供丰富的预训练模型,适用于各种高精准的AI应用场景。结合此前创建的真实或合成数据,NVIDIA TAO(训练-适配-优化)可以使用这些预模型进行迁移学习,实现AI应用场景从无到有。最后使用Triton快速部署这些AI应用模型。

图5.基于Jetson的快速AI模型应用构建流程
通过以上流程,针对不同的场景,利用Jetson-JetPack的结合,实现对AI应用场景的赋能。
1
END
1
