产品中心
Product


助力世界性能超强的工作站
NVIDIA RTX™ A6000 在 NVIDIA Ampere 架构的基础上构建而成,可为设计师、工程师、科学家及艺术家提供处理图形和计算密集型工作流程所需的一切性能。RTX A6000 搭载最新一代的 RT Core、Tensor Core 和 CUDA® Core,可提供远超以往的渲染、AI、图形和计算性能。NVIDIA RTX 已通过众多专业应用认证,经由领先的独立软件供应商 (ISV) 和工作站制造商测试而成,并由一支覆盖全球的支持专家团队提供支持,是要求苛刻的企业部署的理想视觉计算解决方案。
配置及亮点
1. NVIDIA AMPERE 架构
NVIDIA® RTX™ 技术彻底变革了专业视觉计算。NVIDIA Ampere 架构建立于 RTX 的强大功能之上,可显著提高渲染、图形、AI 和计算工作负载的性能。NVIDIA Ampere以追求完美为设计目标,并且包含先进的创新技术,可令RTX 在处理专业工作负载时的表现更上一层楼。
2. 第二代 RT Core
第二代 RT Core 的吞吐量高达上一代的两倍,并能同时运行光线追踪和着色或降噪功能,从而大幅加快电影内容的逼真渲染和产品设计的虚拟原型创建等工作负载的运行速度。这项技术还可提升光线追踪动态模糊的渲染速度,从而更快获得结果,并增加视觉准确度。
3. 第三代 Tensor Core
全新的 Tensor Float 32 (TF32)精度可提供五倍于前代精度的训练吞吐量,无需更改代码即可加速 AI 及数据科学模型训练。可为结构化稀疏提供硬件支持,从而使推理吞吐量翻倍。Tensor Core 还为图形处理引入了 AI,为选定应用带来了 DLSS、AI 降噪和增强编辑等功能。
4. 第三代 NVLink 技术
借助第三代 NVIDIA NVLink®技术,用户可以连接两个 GPU以共享 GPU 性能及显存。凭借高达 112 Gb/s 的双向带宽和高达 96GB 的组合显存,专业人士可以处理大型的渲染、AI、虚拟现实及视觉计算工作负载。新的 NVLink 连接器还具有更低矮的外形,可在更多型号的机箱中实现 NVLink功能。
5. 基于 NVIDIA AMPERE 架构的 CUDA CORE
NVIDIA Ampere 架构的 CUDA® Core 将单精度浮点(FP32) 的运算速度提升了一倍,与 Turing GPU 相比,可带来高达两倍的能效提升。这为 3D 模型开发等图形工作流程,以及计算机辅助工程(CAE) 桌面模拟等计算工作流程带来了显著的性能提升。
6. PCI EXPRESS 4.0
基于 NVIDIA Ampere 架构的 GPU 支持 PCI Express 4.0(PCIe 4.0),后者可提供两倍于PCIe 3.0 的带宽。这提高了从CPU 内存传输数据的速度,可更好地执行 AI 和数据科学等数据密集型任务。更快的 PCIe性能还能加速 GPU 直接内存访问 (DMA) 传输,从而能让支持视频的设备通过GPUDirect® 更快速地传输视频数据,并利用 GPUDirectStorage 加快输入 / 输出 (I/O)速度。
性能规格
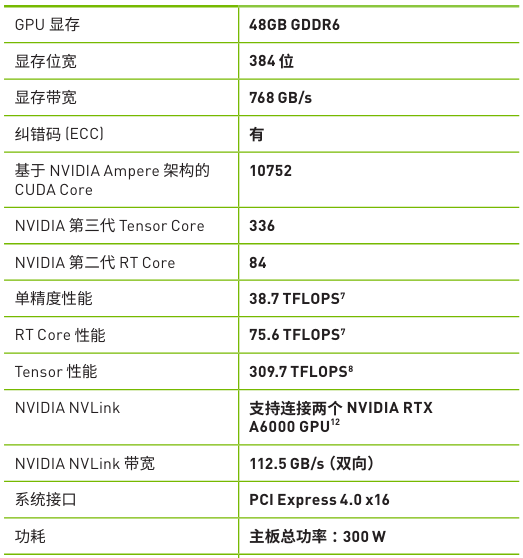
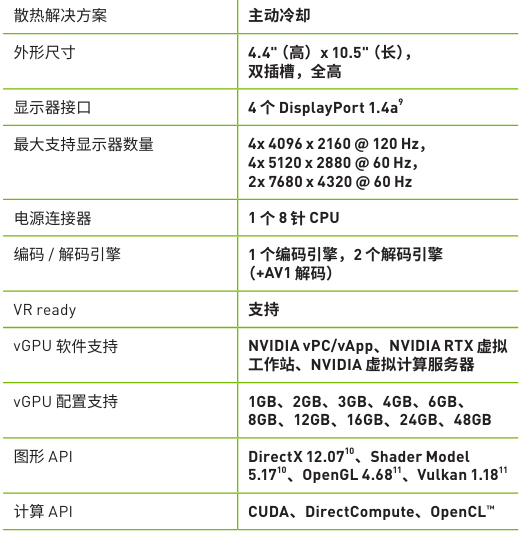
* 与 NVIDIA 产品相关的图片或视频(完整或部分)的版权均归 NVIDIA Corporation 所有。
